


插件描述:用户输入中文,自动生成拼音,点击确定按钮,计算出这个姓名对应的唯一编号
说明:用户输入中文,自动生成拼音,点击确定按钮,计算出这个姓名对应的唯一编号
关键代码:
/*汉字转化成拼音*/
function getPinYinByName(l1) {
var l2 = l1.length;
var I1 = "";
var reg = new RegExp('[a-zA-Z0-9\- ]');
for (var i = 0; i < l2; i++) {
var val = l1.substr(i, 1);
var name = arraySearch(val, PinYin);
if (reg.test(val)) {
I1 += val;
} else if (name !== false) {
I1 += name;
}
}
I1 = I1.replace(/ /g, '-');
while (I1.indexOf('--') > 0) {
I1 = I1.replace('--', '-');
}
return I1.toLowerCase();
}/*通过拼音计算编号*/
function getCodeByPinYin(str) {
var len = str.length;
var base = 0;
for (var i = 0; i < len; i++) {
base += str.charAt(i).charCodeAt(0);
}
return (base < 1000 ? base*7 : base);
// console.log(base < 1000 ? base*7 : base)
}
PREVIOUS:
NEXT:
相关插件-自动完成
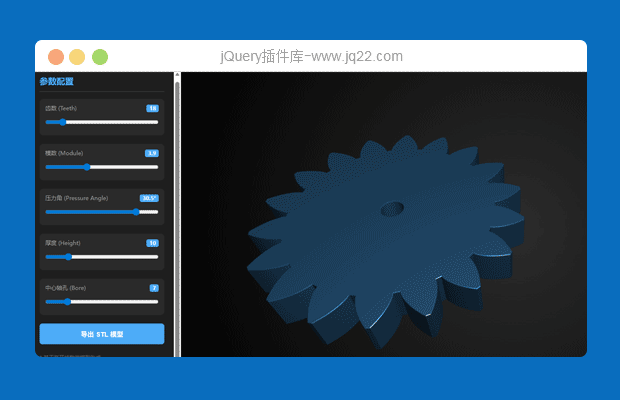
工业级参数化齿轮生成器
类似MakerWorld 的“参数化模型生成器(Parametric Model Maker)”,其核心技术栈通常是 OpenSCAD + WebAssembly (WASM) + Three.js。 MakerWorld 的这个功能本质上是在浏览器端运行了一个 OpenSCAD 引擎,通过修改 .scad 文件中的变量,实时重新渲染 3D 模型。
自动完成


讨论这个项目(7)回答他人问题或分享插件使用方法奖励jQ币 评论用户自律公约

许尊少 0
2018/3/19 11:59:46
此案例只展示常用汉字转换,特殊文字请参考《字符的Unicode表示法》,由于ES5中JavaScript允许采用\uxxxxx形式表示一个字符,其中xxxx表示字符的码点,但是,这种表示法只限于\u0000-\uFFFF之间的字符,超出这个范围的字符,必须用2个双字节的形式表达。JavaScript内部,字符以UTF-16的格式储存,每个字符固定为2字节,对于那些需要4个字节储存的字符(Unicode码点大于0xFFFF的字符),JavaScript会认为它们是2个字符。
例如:
var s = '吉'; s.length; //2 s.charAt(0); // ' ' s.charAt(1); // ' ' s.charCodeAt(0); // 55362 s.charCodeAt(1); // 57271
上面的代码中,汉字“吉”的码点是0x20bb7,UTF-16编码为0xD842 0xDFB7(十进制为55362 57271),需要4个字节储存,对于这种4个字节的字符,JavaScript不能正确处理。
以上就是解释为什么此案例有时候会解析不出正确的拼音。
许尊少0
2018/3/19 12:01:01
-
比如说:输入“?”
许尊少0
2018/3/19 12:01:33
-
zhe 吉吉(打不出来zhe这个汉字)


FlyTigerJQ 0
2017/12/2 22:41:36
演示第一次,一个错音......................
许尊少0
2018/3/19 12:04:04
-
请查看我最新回复
😃
- 😀
- 😉
- 😥
- 😵
- 😫
- 😘
- 😡
- 👍
- 🌹
- 👏
- 🍺
- 🍉
- 🌙
- ⭐
- 💖
- 💔
😃
取消回复
- 😀
- 😉
- 😥
- 😵
- 😫
- 😘
- 😡
- 👍
- 🌹
- 👏
- 🍺
- 🍉
- 🌙
- ⭐
- 💖
- 💔
